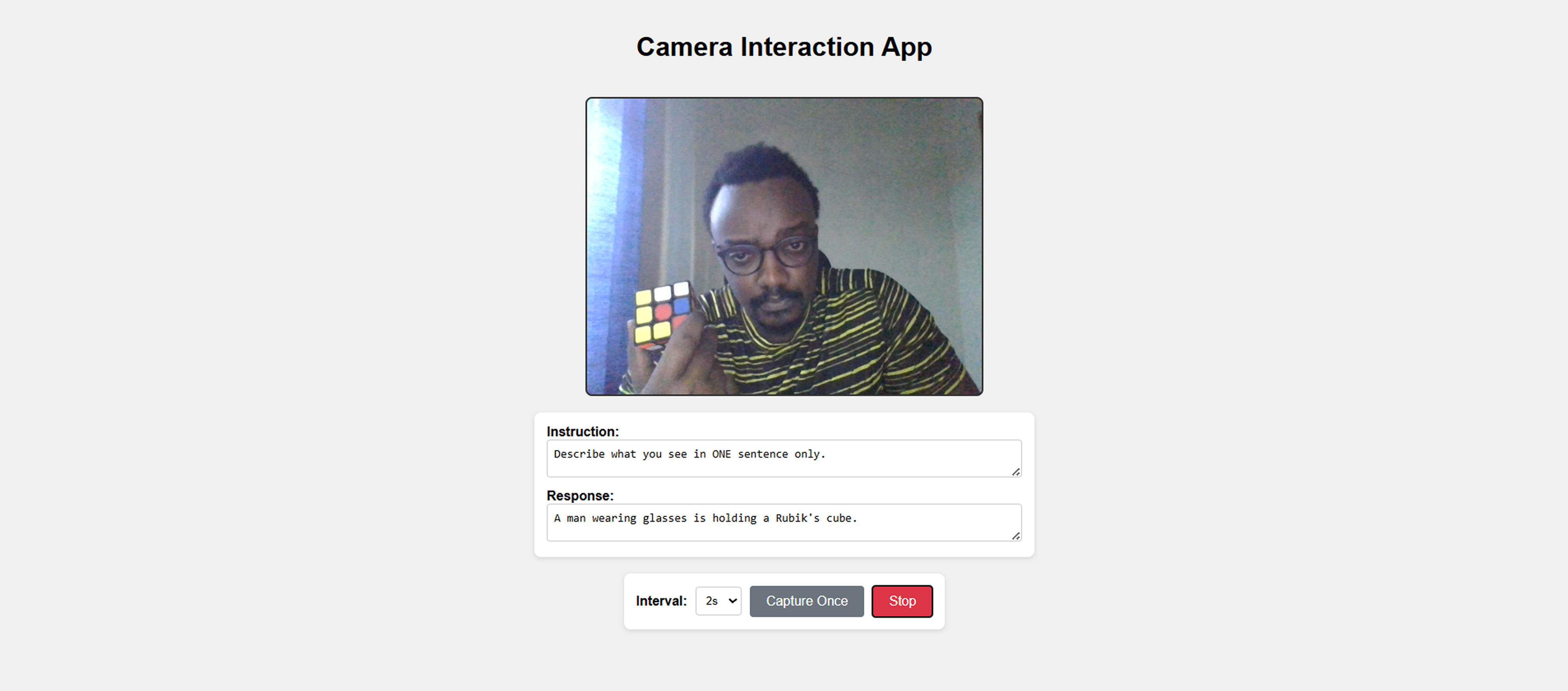
LocalVision – High-Performance Edge Inference
LocalVision is a proof-of-concept system designed to shatter the hardware barriers usually associated with running Vision-Language Models (VLMs). By leveraging highly optimized inference engines, this project enables real-time video description and analysis on consumer-grade hardware, proving that you don't need enterprise clusters to run multi-modal AI.
🛠 Tech Stack
- Core Model: SmolVLM (Lightweight Vision-Language Model)
- Inference Engine: llama.cpp (Custom build with GGUF support)
- Compute Strategy: Hybrid CPU/GPU Offloading
- Environment: Local Python Runtime
⚡ Engineering Highlights
- Resource Efficiency: Successfully runs a VLM (typically requiring 5GB+ VRAM) on constrained GPU hardware by intelligently splitting layers between the CPU and GPU.
- Latency: Achieves smooth, continuous inference speeds comparable to cloud APIs, but running entirely on the edge.
- Optimization: Utilizes quantization and the
llama.cppbackend to maximize throughput on modest architectures, paving the way for effortless performance on M2/M3 chips.
🚀 The Breakthrough
This project demonstrates that "Edge AI" is ready for complex visual tasks. It serves as a blueprint for developers looking to integrate video understanding into local apps without incurring massive cloud costs.
🔗 Source Code: github code



